
The Phantom of the Opera is there, inside my mind.
Caching? Huh?
Caching is the process of storing data in the cache. The cache is a temporary storage area relatively small in size with faster access time.
Whenever your application has to read data it should first try to retrieve the data from the cache. Only if it’s not found in the cache then it should try to get the data from the data store. Caching improves latency and can reduce the load on your servers and databases.
Caching can be done at different levels
⚫ Client Caching Caches are located on the client side like OS, Browser, Servers acting as a client for someone like Reverse-Proxy.
⚫ CDN Caching CDN(Content Delivery Network) is also used as a cache which sits between origin servers and clients. CDNs are used to cache static files like HTML, CSS, JavaScript, image, video, etc.
⚫ Web Server Caching Web servers can also cache requests, returning responses without having to contact application servers.
Database Caching Database by default includes some level of caching in default configurations which are optimized for the generic use case. These configurations can be tweaked to boost the performance for a specific use case.
Application Caching In application caching, the cache is placed between application and data stores. These caches are basically in-memory key-value stores like Memcached and Redis. Since the data is held in RAM, it is much faster than typical databases where data is stored on disk. In this blog post, we will mostly talk about application caching.
There are two patterns of caching the data in application caching.
Click here for a quick read-up on its basics incase you’re not already familiar with bash.
Note that bash is not the only kind of shell. There are other shells out there as well. This diagram helps give a picture of the history of bash:
Just dropping this FAQ link here for those questions I can’t answer because I have disabled comments functionality on this site lol.
Patterns of Caching
- ➊ Caching Database Queries: This is the most commonly used caching pattern. Whenever you query your database, your store the result dataset in the cache. Each result dataset will have a hashed version of the query as the cache key. Every time you run the query, you first check if cache-key is already in the cache.
If it’s in the cache return it from there otherwise fetch the result from the database and store the result dataset in the cache for future queries. The main issue with this pattern is the cache invalidation. It is hard to invalidate the cached result when you cache a complex query result. When one piece of data changes (for example, a table row) we need to invalidate all cached queries which include that row.
➋ Caching Objects: In objects caching pattern, you store the data as an object as you do in your application code (classes, instances, etc.). Your class can assemble a dataset from your database and then you can store the instance of the class or the assembled dataset in the cache. Some examples of objects that can be cached are User Sessions, Fully Rendered Web pages, Activity Streams, User Graph Data.
Since cache data is stored in RAM and RAM size is more limited than disk. For better utilization of the caches, we need to update the caches in an optimized way so that it stores more relevant data and remove others. This is called cache-invalidation. Cache invalidation is a difficult problem, there is additional complexity associated with when to update the cache.
There are different cache update strategy. You should determine the one which works best for you.
Cache-Aside
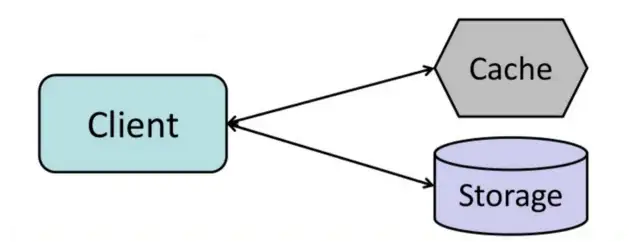
This is the most commonly used cache update strategy in applications. In this update strategy, cache sits aside and an application talks to cache and data store directly. It is also known as lazy-loading. Application logic first checks in the cache before hitting the database. It is mostly used with an application with read-heavy workloads.
Application does following:
- Application checks for the data in the cache
- If data is found in the cache then it’s a cache-hit. Data is read from the cache and returned to the client.
- If data is not found in the cache then it’s a cache-miss.The application reads the data from the data store, stores a copy of the data in the cache and returns it to the client.
Pros
- An application can work even after the cache failure but the performance will be degraded as it has to fetch all data from the data store.
- Due to lazy loading only requested data is cached which avoids filling up the cache with data which is not requested.
Cons
- Each cache-miss is three trips, which can cause a noticeable delay.
- In cache-aside strategy, data is directly written to a data store which can make cache data stale. This can be mitigated by using a TTL to force to update the data after TTL expires or by using a cache update strategy like write through.
- When a new node is added to the system, it can increase the latency as the cache will empty and most of the queries will result in the cache-miss.
Read-Through
Read-through cache strategy is quite similar to cache-aside accept instead of managing both data store and the cache, delegates data store synchronization to the cache provider. Both cache-aside and read-through loads data lazily on the first read.
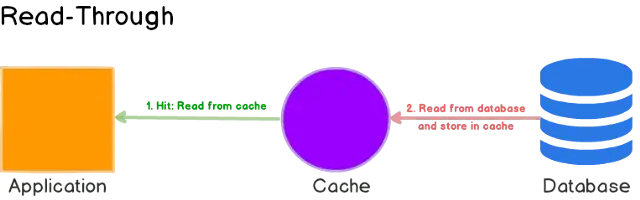
Although read-through and cache-aside are very similar there are two key differences between them.
➊In cache-aside, the application is responsible for fetching data from the data store and populating the cache. In read-through, this logic is usually supported by the library or stand-alone cache provider.
➋Unlike cache-aside, the data model in the read-through cache cannot be different than that of the database.
Read-through cache also works best for read-heavy workloads. It has similar pros and cons as cache-aside cache strategy.
Then we can go to the next step.
Write-through
In this strategy, an application uses the cache as the main data source to read and write. Cache sits between application and data store. The cache is responsible for reading and writing to the database.
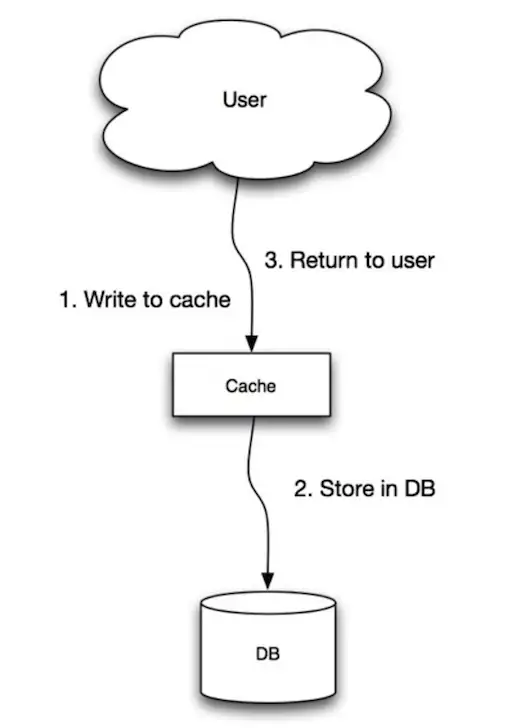
In write-through cache application does following:
- Application adds or updates an entry in the cache
- Cache synchronously writes entry to the data store
- Cache returns the entry to the application
Write-through slows overall operation due to the write operation which writes data to the the cache first and then synchronously to the data store. Once data is written to cache, subsequent reads for the same data is fast.
Pros
Data in the cache is not stale.
Cons
When a new node is created due to failure or scaling, the new node will not have cache entries until the entry is updated in the database.
Most data written to cache might never be read. This can be minimized with TTL.
Write-Behind (Write-Back)
In write-behind, the application does the following:
• Add/update the entry in the cache • Asynchronously write an entry to the data store, improving write performance. It is used in an application having write-heavy workloads.
Pros:
• Write-behind cache improves write performance of the application
Cons:
•There is a possibility of data loss if cache goes down before data is written to the data store. •A write-behind cache is difficult to implement compared to other cache update strategy.
Refresh-ahead
In refresh-ahead strategy, the cache is configured in such a way that it automatically refreshes any recently accessed cache prior to its expiration. Refresh-ahead can result in reduced latency if the cache can accurately predict which items are likely to be needed in the future.

Pros:
•Reduced latency.
Cons:
•Not accurately predicting which items are likely to be needed in the future can result in reduced performance than without refresh-ahead.
References :


 Click all the links here to see how deep you can go down the rabbit hole.
Click all the links here to see how deep you can go down the rabbit hole.